什么是数据库索引?索引有什么用?为什么索引查询效率高?
日常开发中,对于数据的查询如果需要优化,常听说要加个索引。但是为什么加了索引,数据的查询就快了呢?那是不是加了索引就一定会是有效或者有利的呢?
索引介绍
Oracle中常见有BTREE索引,位图索引和函数索引。
先介绍一下Btree索引。词如其名,就从它的tree结构说起。
建BTREE索引其实是先拿出所有数据排序,将有序的索引列的值和rowid存进Oracle的各个数据块中,形成索引块,存在内存中。这些数据块以树结构的形式组织起来,父节点只记录子节点的键值位置信息,不存具体数据,所以,只有叶子块存具体数据(索引列数据和rowid)。其他非叶子节点只记录位置信息,占用空间非常小,所以索引块即使存了很多数据,这颗树的高度其实并不高。
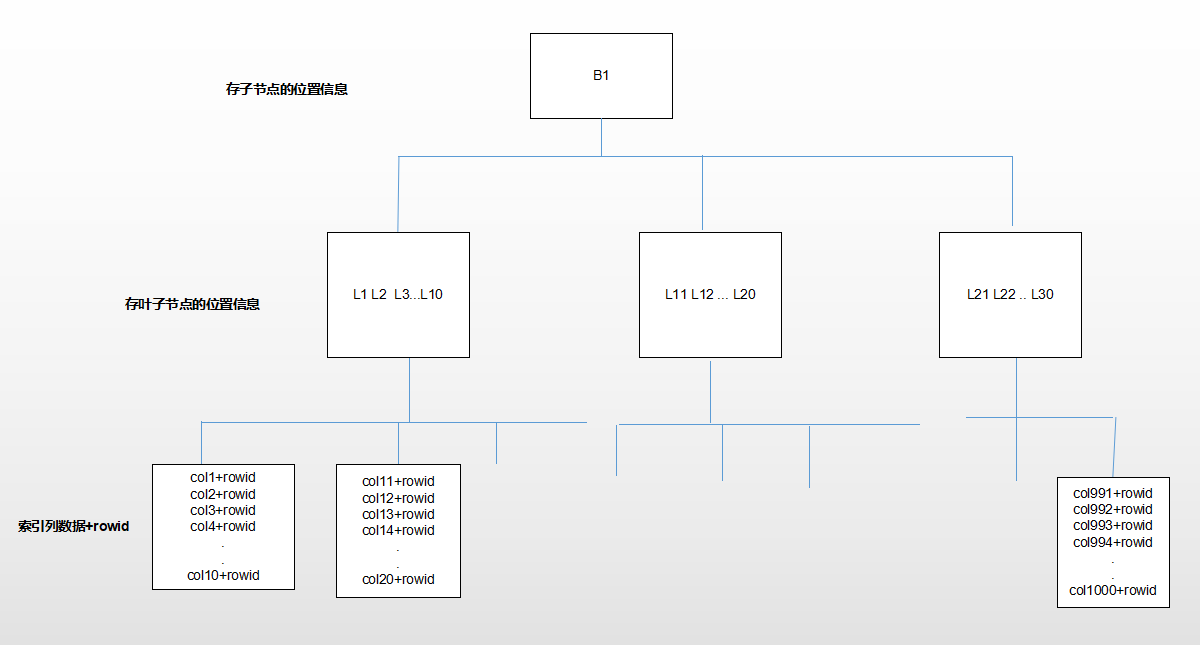
索引查询
查询的时候,根据树的结构去查询,产生的逻辑读的次数也就是树的高度,走索引的逻辑读不会很多,产生的IO少,所以肯定比全表扫描要效率高。
注意:如果索引列包含空值,是不会走索引的。所以,在一些查询中,要想走索引,需要加上条件“索引列 is not null”或者修改表字段属性为非空。
例如:没建索引之前,对于统计函数肯定是全表扫描:
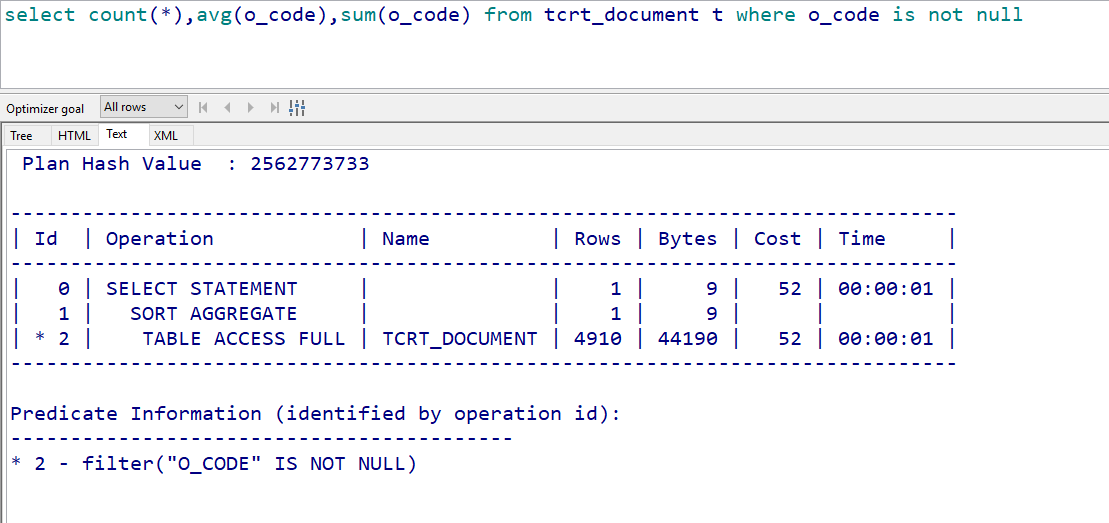
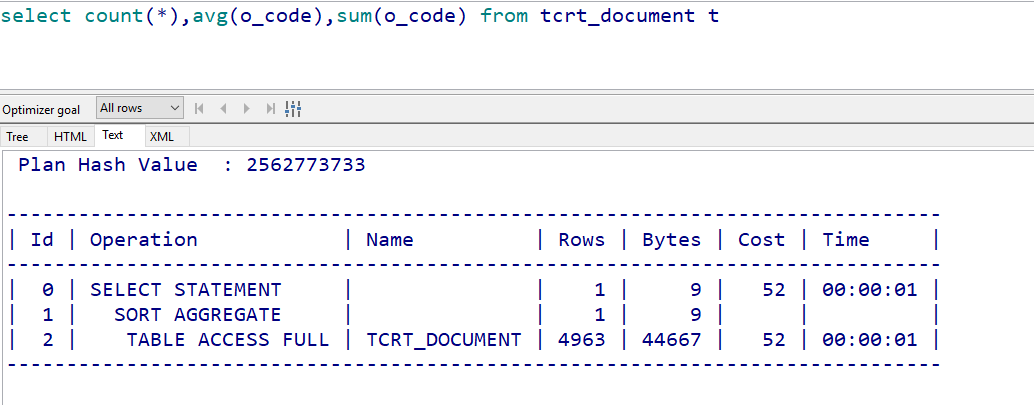
建索引之后,如果我们不对空值进行筛选,是不走索引的:
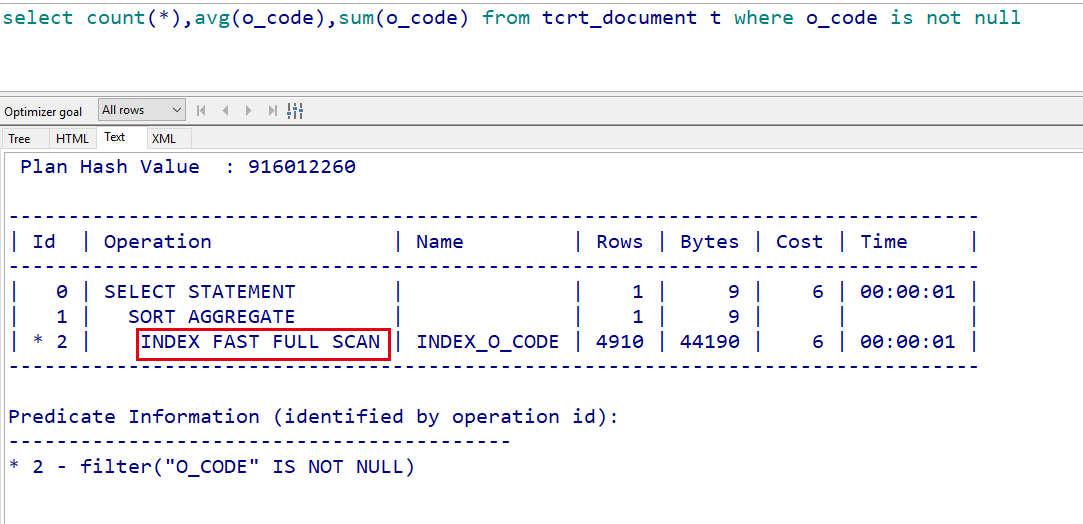
对于空值进行排除后,可以看到走索引了:
在最大最小值的查询中,索引也是优化的一个手段。没建索引之前:
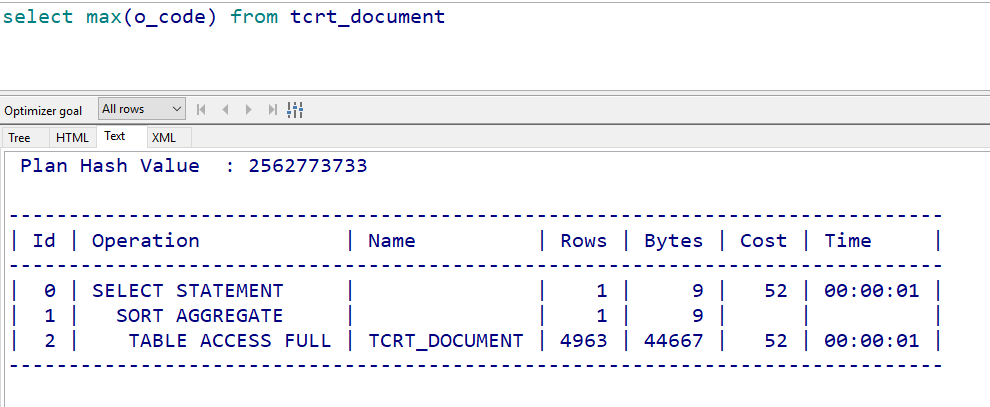
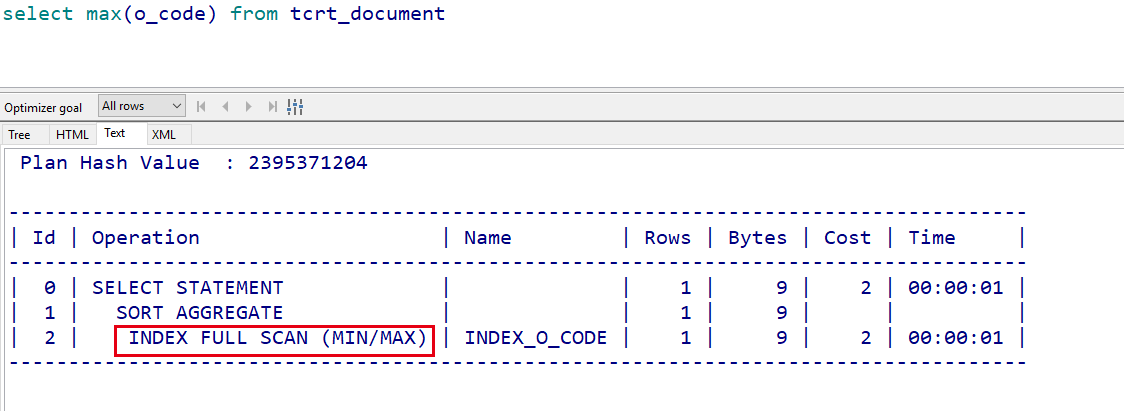
建了索引之后,因为索引的有序特性,直接去索引树的最右或最左叶子节点找一遍就可以了:
再看select具体字段和select *的区别。
比较下面两个查询:
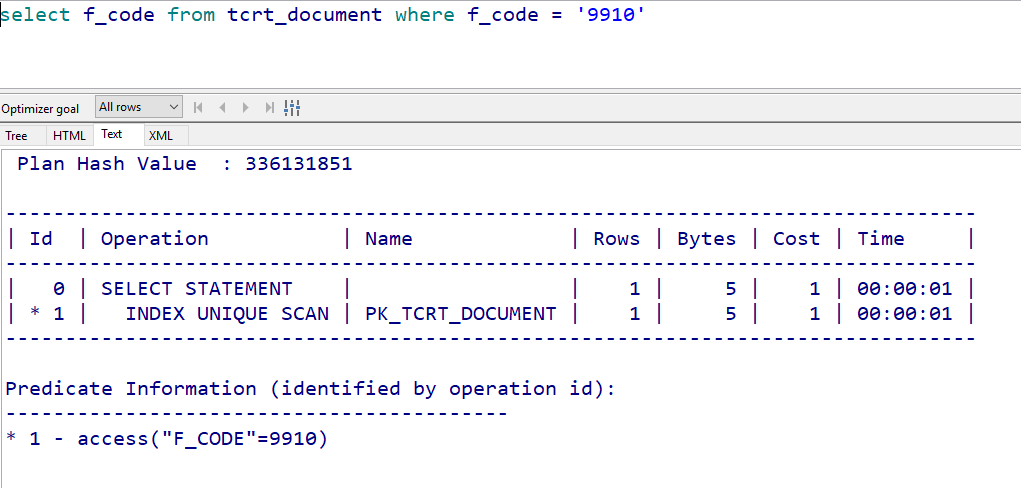
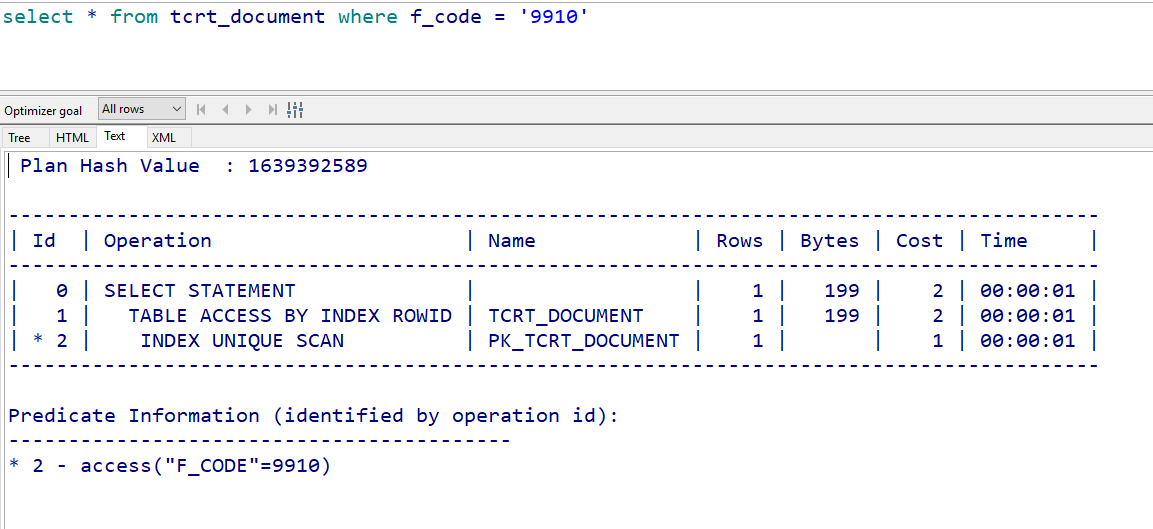
上面我们说过,索引储存了索引列和rowid的数据,如果我们只取索引列的数据,则,访问到索引块即取到我们需要的数据了;如果还需要取其他字段的数据,在索引中找不到,则会存在一个去表中取数据的操作,即“TABLE ACCESS BY INDEX ROWID ”,多产生的读取操作必然会增加消耗,所以如果有些字段必须展现,又数据量很小,可以考虑建联合索引。
既然索引是有序的,那我们的order by操作也可以随之进行优化了:
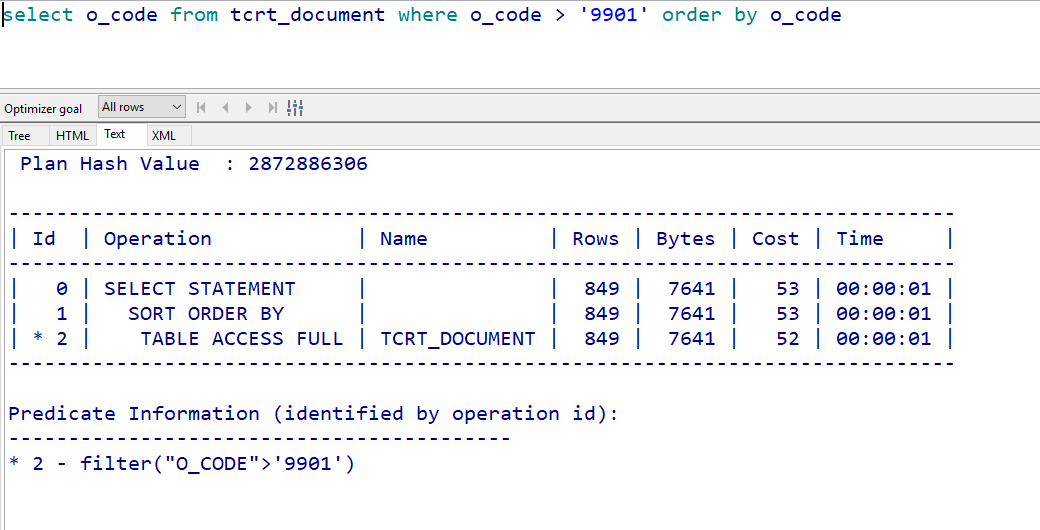
在排序列上建索引之后:
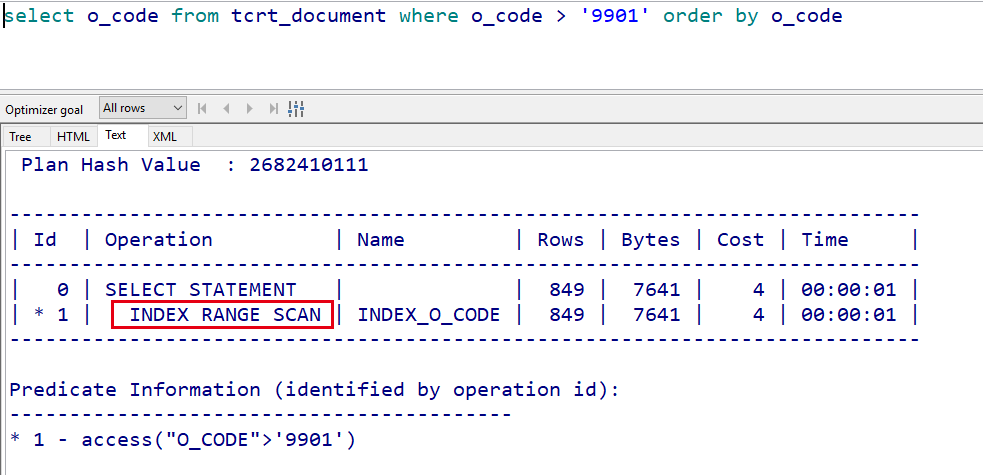
可见走索引的排序要比全表扫描的排序消耗小很多。
联合索引
上面说到,为了避免回表,我们可以建联合索引,但组合列最好不要超过3列,返回的组合列越少越高效;
问题也随之而来,组合列中哪个列在前哪个列在后呢?
一般,在等值查询情况下,谁在前谁在后没关系;如果一列是范围查询,一列是等值查询,等值查询列在前效率高;联合索引中,如果针对其中一列的查询单列比较多的时候,单列查询在前。比如在某表中,想对其code和pcode字段建联合索引,但是业务中有大量的查询pcode的单列查询操作,则联合索引应该将pcode放在前面比较合适。
索引的危害
上面说了这么多索引的优点,那是不是建索引一定是有利的呢?
因为索引的有序特性,索引索引越多,为了维持索引有序,更新数据受到影响就会越大:
insert:每插入一条数据,就要维持索引有序,因此,索引对于插入操作有弊无利;
delete:删除数据,如果数据量很大,对于定位要删除的少量数据,条件列是索引列是有利的。如果删除大量记录或者索引列过多,对于删除操作是有弊端的;
update:如果更新非索引列,则无影响;如果更新索引列,定位和更新索引列则和delete操作类似。
因为是将数据拿出来排序并且保存到数据块中,建索引时会锁表,以免建索引过程中数据更新造成影响,所以,建索引尤其是大数据表,不要在使用高峰期建。
