避免低效率sql的一些细节
前段时间公司有个项目,需要去客户那里面试。客户问了个SQL优化问题,问如何写出一个效率高的SQL,这个问题虽然很广泛,但现在想来,应该是可以回答的更好的。 如何写好SQL,让SQL的执行效率更高,应该注意以下几点:
- 单条SQL不宜超过100行,主要是可维护性和可读性。(虽然很多业务的要求让这个建议很难做)
- 尽量不要使用select * ,而是具体字段
按需所取,节省资源,减少网络开销;如果是只查询索引列,造成回表操作
- 子查询不宜嵌套超过3层
子查询嵌套过多,可能会导致解析过于复杂,产生错误的执行计划
-
表关联需要考虑连接和限制条件的索引
- 同一模块避免出现大量相似之处
一般这种SQL比较可疑,一般可优化,如with语句
- 尽量避免使用or的连接条件
or的限制列有非索引列时,使用or可能会造成索引失效,可使用union all代替
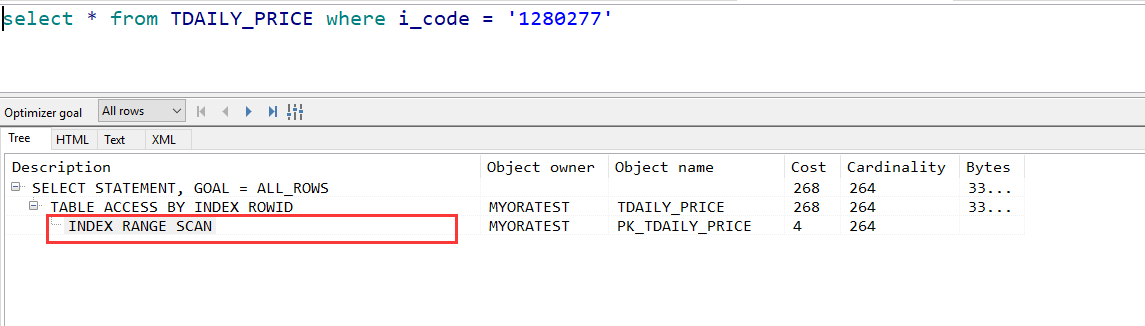
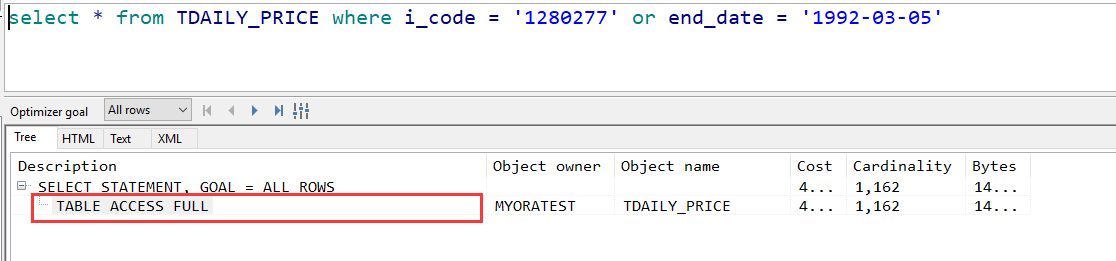
- 尽量避免对列进行运算
使索引失效,也降低效率
- 尽量批量提交
commit做的事情开销并不大,是将redo buffer写入到redo log file中(具体一套commit操作可自行查资料),不管是多大批量commit,都是执行这个操作,所以尽量选择批量提交
- 使用绑定变量
利用变量代替具体的值,SQL语句就能只解析一次,执行n次,减少了n-1次解析的时间
- 优化like语句
尽量不要把%放在前面
- 尽量避免在索引列上使用not, <>, !=等
索引只能找到在索引上的,不能找到不在的
- 不要有太多的表关联
连表越多,编译的时间和开销越大;拆分成几个较小的执行,可读性更高
- 尽量数据库分页
- 关联或where条件中,注意数据类型的匹配
如where o_type = 1,但o_type是varchar类型,执行计划会有to_number(o_type)的操作,违反7
